SemrushBot,AhrefsBot,MJ12bot,是什么爬虫?能不能屏蔽。最近有一波SemrushBot,AhrefsBot,MJ12bot蜘蛛,天天访问小白的小站。搜索了下原来又是一个国外的SEO分析爬虫。如果你的站点面对的是国内客户,完全可以直接屏蔽。
互联网上有一种说法,网上大约50%的流量都是爬虫的贡献,包括所说善意的爬虫如各大搜索引擎,(其实有些搜索引擎光爬不怎么收录也让人烦),还有些恶性爬虫不会带来流量,还因为大量的抓取请求,造成主机的CPU和带宽资源浪费,所以需要对其屏蔽。
下面来看看怎么样屏蔽那些无用的垃圾蜘蛛爬虫。
1:使用robots.txt屏蔽垃圾蜘蛛
将下面代码复制到网站根目录下的robot.txt文件里,这样可以屏蔽掉以上的垃圾蜘蛛对于网站的抓取。
User-agent: AhrefsBot
Disallow: /User-agent: DotBotDisallow: /User-agent: SemrushBotDisallow: /User-agent: UptimebotDisallow: /User-agent: MJ12botDisallow: /User-agent: MegaIndex.ruDisallow: /User-agent: ZoominfoBotDisallow: /User-agent: Mail.RuDisallow: /User-agent: SeznamBotDisallow: /User-agent: BLEXBotDisallow: /User-agent: ExtLinksBotDisallow: /User-agent: aiHitBotDisallow: /User-agent: ResearchscanDisallow: /User-agent: DnyzBotDisallow: /User-agent: spbotDisallow: /User-agent: YandexBotDisallow: /
robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的蜘蛛,此网站中的哪些内容是不应被搜索引擎的蜘蛛获取的,哪些是可以被蜘蛛获取的。因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。如果想单独定义搜索引擎的蜘蛛访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。robots协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
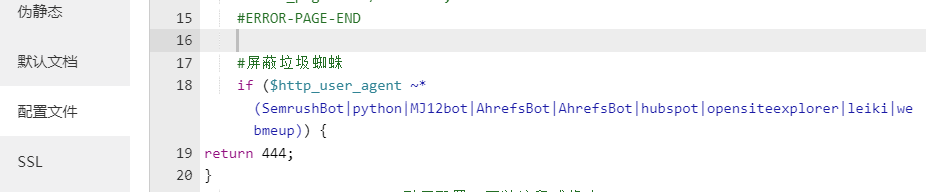
2:你是 linux nginx 服务器配置,可以在nginx配置文件里面加个客户端判定。以BT宝塔为例, 宝塔面板可以在 网站配置里加上屏蔽 这些垃圾蜘蛛在来的时候 只能得到444 没有任何数据 然后就不会再来了
if($http_user_agent~*(SemrushBot|python|MJ12bot|AhrefsBot|AhrefsBot|hubspot|opensiteexplorer|leiki|webmeup)){
return444;
}
不影响正常蜘蛛抓取
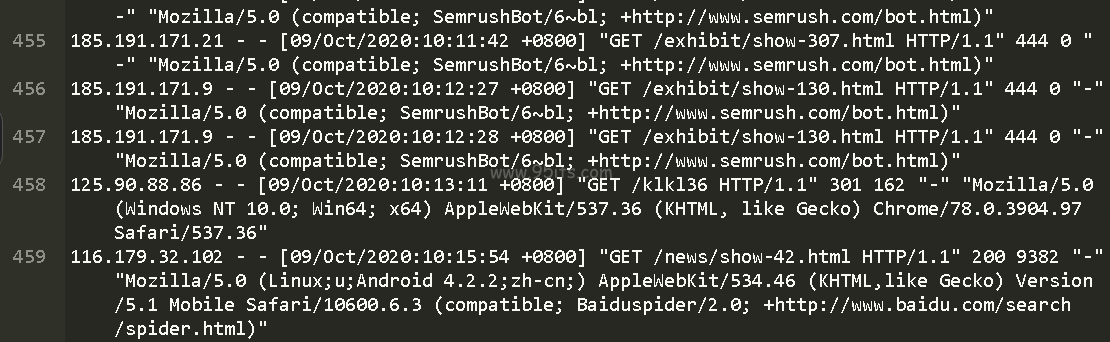
这样 谷歌蜘蛛,百度蜘蛛,搜狗蜘蛛,头条蜘蛛都是 显示正常抓取。正常发送数据
